Designing Machine Learning Solution For Course Recommendation
data-science system-design recsys interviews I have been reading books on machine learning and software system design. I have also been opportune to interview data scientists and machine learning engineers, one of my favorite question which is motivated from the book Machine Learning System Design Interview is:
Suppose you are a Data scientist at LinkedIn, how would design a machine learning solution that would recommend courses to users on Linkedin Learning?
It is essential never to lose sight of the main goal of the course recommendation system which is to acquire new learners by showing them highly relevant courses. However, to do this, there are few challenges we may have, and they include lack or insufficient labelled data that contain user-course preferences. Ways to deal with this include:
-
Collection of user activities data that include browsing and click history. We can use these signals as implicit labels to train a model. It is also important to note that as we are building the Linkedin learning system, we don’t have any engagement signals yet and this phenomena is referred to as the cold start problem.
-
Collection of user responses filled during on-boarding process, that is, we ask learners which skills they want to learn or improve. However, in practice this data is insufficient.
To illustrate the idea behind the recommendation system we intend to create, let’s create a hypothetical example of a learner - Babs. Suppose Babs has the following skills on his LinkedIn profile: Data analysis, Statistics, Big data. Assume we have two courses: Data Engineering and English literature, it makes sense that Data Engineering would be a better recommendation to Babs because it is more relevant to his skillset.
This leads us to one idea: we use skills as a way to measure relevance. In other words,
If we can map Course to Skills and map Users to Skills, we can measure and rank relevance accordingly.
This idea is visualised in the following figure and subsequently explained.
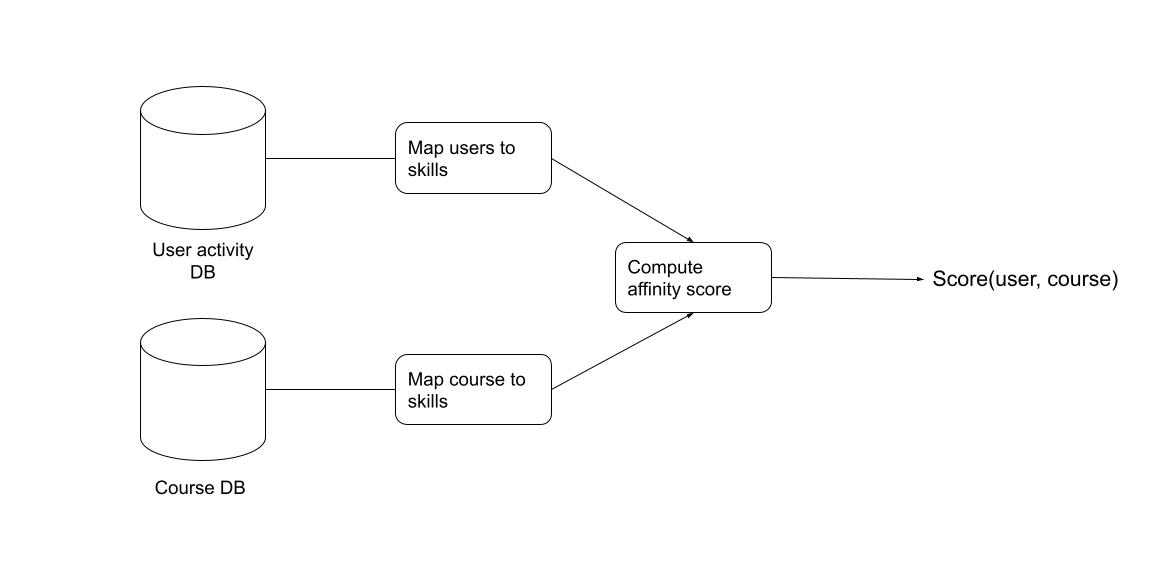
Course to Skill Mapping
There are various techniques to build the mapping from scratch, among them are:
1. Manually tagging using taxonomy
Here all LinkedIn Learning courses are tagged with categories. For example, a course like Data Science can be mapped to skills such as data analysis, statistics, SQL, etc. We ask taxonomists to perform the mapping from categories to skills. This approach help us to acquire high-precision human generated courses to skill mapping. On the other hand, it doesn’t scale i.e. low coverage.
2. Leverage LinkedIn skill taggers
We can also leverage LinkedIn skill taggers features to extract skill tags from course data.
3. Use Supervised model
We can also train a classification model such that for a given pair of course-skill, it returns 1 if the pair is relevant and 0 otherwise. To do this, we have to collect samples from 1 and 2 above as positive training training class labels. We then take random samples from other data and treat them as negative labels. In addition, we create features for the model using course data (title, descrioption, categories, etc). However, this method has a major drawback, it relies heavily on the quality of the skill-taggers and one logistic regression model might not be able to capture the per-skill level effects.
4. Use Semi-supervised learning
- We learn a different model for each skill, as opposed to one common model for all (course, skill) pairs.
- Data augmentation. Leverage skill-correction graph to add more positive labelled data. For example, if SQL is highly relevant to Data Analysis skill then we can add Data analysis to training data as positive label.
Evaluation (offline) metrics
- Skill coverage: measure how many LinkedIn standardized skills are present in the mapping
- Precision and recall: We treat course to skill mapping from human as ground truth, then evaluate the classification models using precision and recall.
User to Skill Mapping
1. Member to skill via profile
LinkedIn users can add skills to their profile by entering free-form text or choosing from existing standardized skills. This mapping us usually noisy and needs to be standardized. In practice, the coverage is not high since not many users provide this kind of data. We also train a supervised model p(user_inputted_skill, standardized_skill) to provide a score for the mapping.
2. Member to skill using job title and industry
To increase the coverage, we can use cohort-level mapping. For example, suppose Babs work in the retail industry and his job title is Machine Learning Engineer, if he didn’t provide any skillset in his profile, we can infer his skills by taking the skillsets common to Machine Learning Engineers working in the retail industry and this is referred to as cohort-based mapping. We then combine the profile-based mapping using weight combination with cohort-based mapping. The table below is an example of using the profile-based and cohort-based mapping to create a user-to-skill mapping.
| Skill | Profile-based mapping | Weight | Cohort-based mapping | Weight | Final mapping |
|---|---|---|---|---|---|
| SQL | 0.01 | w1 | 0.5 | w2 | 0.01 * w1 + 0.5 * w2 |
| Data analysis | 0.03 | w1 | 0.2 | w2 | 0.03 * w1 + 0.2 * w2 |
The explanation above should be sufficient for an interview. I did not delve into the non-functional software design requirements such as latency, availability and scalability requirements , API design, and so on.
Reference
Machine Learning System Design Interview by Khang Pham
Personalized Recommendations in Linkedin Learning